CPUs are optimized for latency; GPUs are optimized for throughput. They are independent processors, so can and should work on different things at the same time.
Latency - Time taken to complete a single operation or instruction; commonly measured in clock cycles. Lower latency is obviously desirable. Note that latency can be talked of for CPU/GPU computation or memory access - they are two different things. The value of latency of an instruction depends on the type of instruction (integer/floating-point/SIMD). Here we are not referring to a particular type of instruction.
Throughput - Number of operations or instructions completed per unit of time. Again, throughput can refer to computation or memory access. By convention, when we say throughput, we mean computation throughput and that is measured typically in FLOPS (Floating Point Operations Per Second). Higher throughput is obviously better.
The analogue of throughput for memory is called bandwidth. It’s the maximum amount of data transfer that can happen per unit time and these days it’s typically measured in GB/s. Note that bandwidth encompasses the memory device (DRAM/SRAM etc.) as well as the bus speeds.
So here we are - we want higher throughput and lower latency. It may seem like lowering latency would automatically increase throughput and that’s true in theory; in practice there are constraints and trade-offs. We have to decide whether it’s more critical for us to have latency-optimized or throughput-optimized system. Optimizing for one practically leads to sub-optimal performance for the other.
Analogy
Consider an analogy: we want to get from Secretariat in New Delhi (green) to Dwarka (red). We can take either the metro which takes about 75 minutes or use a car which takes 45 minutes. The metro takes longer for us (higher latency) but it transports a lot more people in let’s say an hour (higher throughput). So, the metro is optimized for throughput and the car is optimized for latency. Note that a car is more flexible and can take us to places where the metro doesn’t go.
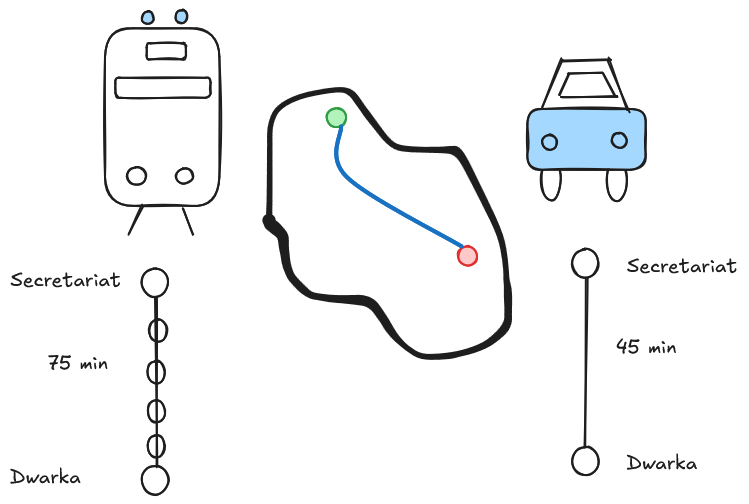
CPUs are the cars - optimized for latency. Context switching between threads is expensive. So the CPU makes an individual thread as fast as possible. By CPU here, we actually mean both the processor and the memory system. Focusing on the processor, there are complex things like branch prediction, out of order execution, prefetching to make the latency low - this makes the cores complex and takes up real-estate on chip. Hence, we only have a few cores on a CPU. The memory hierarchy is elaborate with multiple levels to optimize for latency.
GPUs, on the other hand, are the metros. The cores are simple and hence there can be a lot of them. The focus is on massive parallelism, so throughput is high. Latency for an individual thread may not be great, but for GPU workloads that’s not so important. Even the GPU memory has simpler organization and wider buses to optimize for throughput. Such a system, like a metro, works best when it’s oversubscribed; there is a deep queue of pending threads to be executed.
Asynchrony
CPUs and GPUs are independent processors. They can and should work on different things at the same time. The following is a bad model of how to use a CPU and a GPU together:
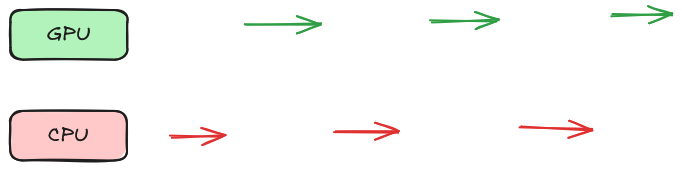
Note how GPU does some computation and then waits for something for CPU - this happens repeatedly. It’s as if the CPU and GPU are operating synchronously. In this case, a much better flow is the following:
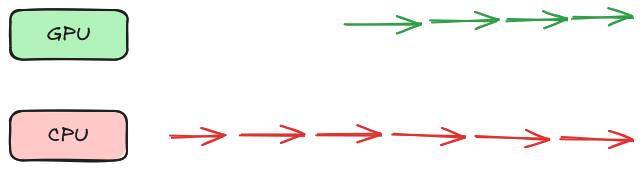
In the above, the CPU issues computation to GPU and then starts working on its own thing separately. There is good utilization of both processors. We say that they are operating asynchronously - we’re aiming for this.
This post was inspired by part of Steve Jones’ talk at GTC 2021. Thanks to Eric for telling me about it.