I’ve been teaching courses on Computer Systems and Operating Systems at Plaksha University. Programming assignments are an integral part of such systems courses. The challenge comes in evaluating the large number of submissions. One can write scripts to score the correctness of code, perhaps by test cases; even performance measures such as execution time or cache memory hits/misses can be easily captured. The harder part is giving feedback on the quality of the code. Usually, TAs annotate the submission indicating how readable or well-organized the program is and whether it makes use of good language conventions. This calls for good programming expertise from the TAs themselves; a lot of effort is also required to give such feedback for a large class.
I wrote a tool called CodeInsight to provide such feedback automatically. It makes use of a suite of state-of-the-art LLMs in an agent-based architecture. Given a problem statement and an assignment program, the tool returns an annotated version of the program, inserting comments at appropriate points, either to suggest improvement or to commend good implementation; the original code remains as it is. The parameters are cleanliness, language conventions, organization, data structures, and use of pointers (for C). It goes without saying that program correctness comes first and foremost; this tool does not check for that.
While state-of-the-art models are good at code understanding, they do make mistakes. If let’s say Claude-3.5-Sonnet is asked to provide feedback in our desired format, three cases can arise:
- provides the correct feedback at the appropriate point
- provides feedback at some point, but that isn’t quite correct or relevant. For instance, it may suggest some optimization that may be valid but isn’t required as part of the assignment
- fails to identify a bad practice where it actually occurs
Besides, different LLMs have different strengths. ChatGPT 4.0 may correctly pick up some points that Claude missed.
Considering these, it seemed appropriate to me to use an agent-based approach. Specifically, I used a multi-agent collaboration design pattern. Andrew Ng puts the idea succinctly: “More than one AI agent work together, splitting up tasks and discussing and debating ideas, to come up with better solutions than a single agent would”. The architecture looks like the following:
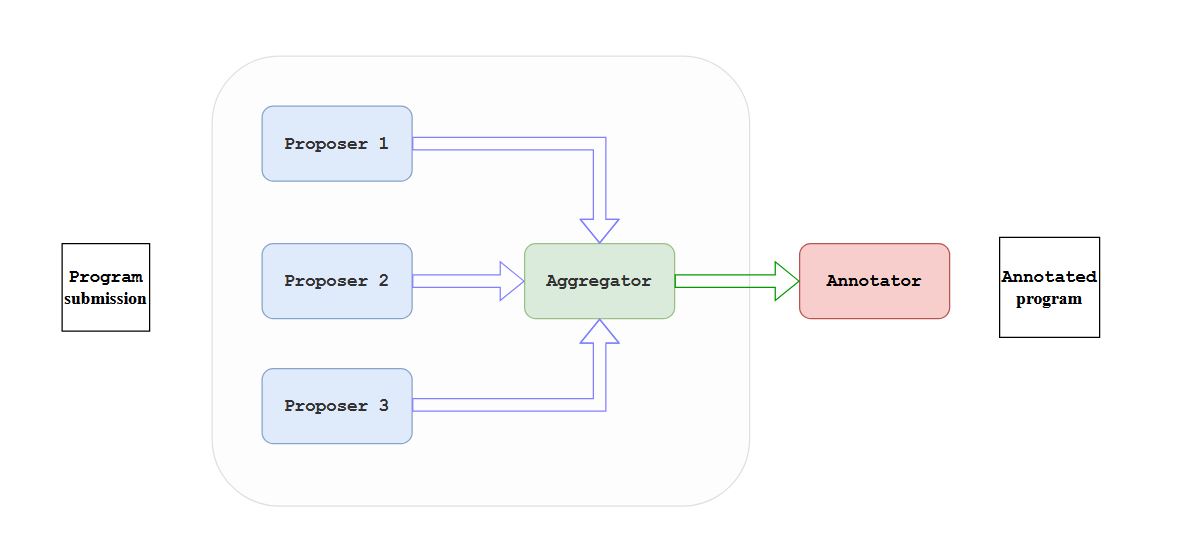
Proposers, aggregators, annotators, and comparators are role names given to LLMs hinting the function they carry out. More details can be found in the home page of the GitHub repository. I’d just like to mention that there are actually 4 proposers (rather than 3 in the figure) and they are distinct models - Claude-3.5-Sonnet, GPT-4o, Mixtral-8x22B, and Llama-3.1-405B. Also in the spirit of breaking down tasks, the proposer-aggregator loop is run once for every evaluation parameter - readability, organization, language convention, etc. Finally, I found that it was critical for the prompts to be detailed and accurate. I made use of this excellent documentation on programming assignment grading from a Stanford course.
There are two challenges with such an agent-based approach - overall system latency and API costs. The first is not an issue for us since we use the tool offline on a batch of assignments. The cost can be a concern when the number of assignments is large. I don’t have cost estimates yet, but I felt it was important to first make the tool output as good as we can. I have yet to check the degradation of performance if we use, let’s say, 2 proposers instead of 4, or the latest suite of smaller models.
The fun part was the system evaluation. I wanted to compare the tool output with sample programs annotated by a good programmer. For the sample programs, I selected 10 C programs written by not-expert programmers (the programs should have scope for us to suggest feedback). I requested two of my good students to annotate those programs with feedback, and also ran the tool on the programs. I let GPT-4o do the comparison and provide a 0 or 1 score based on which of two inputs - tool or human annotation - is better (the comparison prompt was more elaborate). I computed the average win-ratio of the tool for each student. Averaged over both programmers, the win ratio was 5-5. This was encouraging.
Although our tool goes beyond what traditional linters do, it’ll be helpful to incorporate linter output and provide them as part of prompts to proposers. I’d like to do a more exhaustive human comparison testing on more C programs. Once I use it for some assignments in my course, hopefully students’ feedback will give me pointers to improve the tool.